A single-tenant fulfillment center running one client's product catalog can treat wave scheduling as a throughput optimization problem. The goal is simple: maximize picks per hour, minimize travel distance, ship on time. When you introduce a second client, the goal doesn't change — but the constraints multiply. By the time you're running eight clients under one roof, wave scheduling is a constraint-satisfaction problem with per-client SLA commitments, separate inventory locations, distinct pick accuracy requirements, and billing records that have to match pick records to the line item.
Add an autonomous pick cell to that environment, and the wave scheduling architecture has to account for one more constraint: the robot cell has a fixed throughput rate, a defined SKU scope, and zero tolerance for ambiguity in which pick task belongs to which client account. Getting this architecture right from day one is substantially easier than retrofitting it after your first client billing dispute.
Why Single-Tenant Wave Logic Breaks in Multi-Tenant 3PLs
The standard wave scheduling approach — aggregate all open orders into a wave, optimize pick paths by location, release to pickers — assumes homogeneous inventory ownership. In a single-tenant environment, every item in the pick face belongs to the same client and the same order pool. Pick path optimization is purely a travel-distance calculation.
In a multi-tenant 3PL, inventory ownership is not homogeneous. Client A's SKUs and Client B's SKUs may be physically adjacent in the same pick aisle, but they belong to separate order pools with separate shipping cutoff times, separate pick accuracy SLAs, and separate billing records. If your wave logic aggregates across clients before considering ownership, you produce waves where one client's orders are delayed to optimize another client's pick path — and you create a billing attribution problem when pick confirmations don't sort cleanly back to individual client accounts.
The correct architecture is client-segregated wave generation: each client's open orders generate their own wave queue, and those queues are managed independently through the WMS before they are allocated to pick resources — human or robot.
Building Client-Segregated Waves in Practice
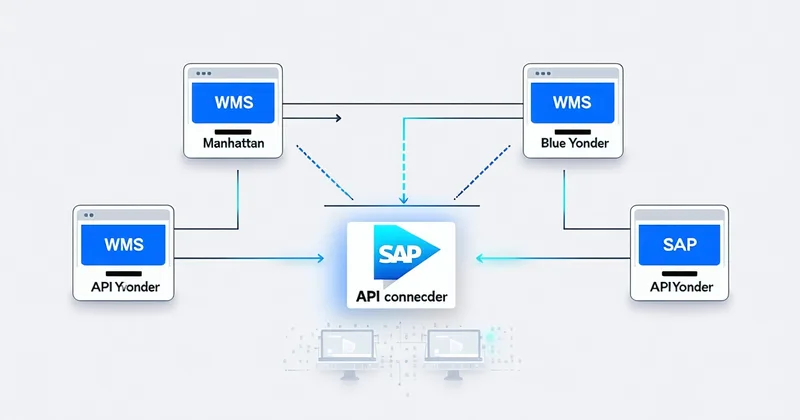
Manhattan Active WMS supports client-segregated wave generation through its warehouse management group (WMG) configuration. Each client is assigned its own WMG, which controls how orders flow into waves, which pick zones they're allowed to use, and which confirmation codes are applied. Blue Yonder's Luminate platform uses similar owner-code logic at the order header level. SAP EWM models this through storage type and warehouse order creation rules.
The key configuration decision in any of these platforms is whether client segregation happens at wave generation or at task assignment. Wave-generation segregation — where each client's orders never enter the same wave — is cleaner and easier to audit. Task-assignment segregation — where a combined wave is later split into per-client task buckets — introduces an intermediate state where commingled order data exists in the system and has to be manually managed if a wave needs to be re-run or partially cancelled.
For multi-tenant 3PLs deploying autonomous pick cells, wave-generation segregation is the correct architecture. The robot cell needs to receive wave releases that clearly identify client ownership at the order line level, so that pick confirmations write back to the correct billing account. If the wave architecture commingles clients before this point, the integration work required to recover per-client accuracy is significant.
Robot Cell Allocation Across Client Waves
Once you have clean client-segregated waves, the next question is: how does the robot cell allocate its throughput capacity across multiple client queues that may all have active waves simultaneously?
There are three allocation models, each appropriate for different 3PL configurations:
Model 1: Client Priority Queue
Client waves are ranked by shipping cutoff proximity. The robot cell works the highest-priority client's queue until that wave's eligible items are complete, then moves to the next priority. This model is simple to manage but can produce unacceptable throughput variation for lower-priority clients if a high-priority client consistently has large waves.
Model 2: Proportional Allocation by Contract Volume
The robot cell allocates throughput capacity in proportion to each client's contracted pick volume. If Client A represents 40% of total contracted picks and Client B represents 25%, the robot cell dedicates approximately 40% and 25% of its capacity to their respective queues during each wave cycle. This model produces more predictable per-client throughput but requires the WMS to enforce the allocation, which not all platforms do natively.
Model 3: SLA-Driven Dynamic Allocation
The robot cell monitors the remaining time-to-cutoff for each client wave and dynamically reprioritizes its queue based on which client is at greatest risk of missing their SLA. This is the most responsive model and the best fit for 3PLs with clients that have tight same-day or next-day cutoff commitments. It requires the WMS integration to surface cutoff time data at the wave level — which is available in Manhattan Active WMS and Blue Yonder Luminate but requires configuration in SAP EWM and may not be available at all in older 3PL Central deployments.
We're not saying Model 3 is right for every operator — we're saying it's the model that produces the least client SLA exposure when order volume is unevenly distributed across client accounts during peak periods. A growing 3PL with clients at similar contract sizes and similar SLA profiles can run Model 1 or Model 2 without meaningful SLA risk.
Exception Handling Across Client Accounts
Exception items — SKUs that fail vision verification, fall outside the pickability envelope, or are unavailable at the expected bin location — need to be routed to a human exception station with full client attribution preserved. This sounds straightforward but creates a specific integration challenge: the exception station needs to know which client account the item belongs to so that human pick completion is attributed to the correct billing record.
The exception routing event sent by the pick cell should include: order line ID, client account code, SKU, expected bin location, and failure reason code. When the human picker completes the exception pick, they confirm against the same order line and client code. This preserves the billing record integrity whether the pick was completed by the robot or by a human exception handler.
In a facility running a pilot deployment with a mid-size regional 3PL operator across five client accounts, we found that roughly 8–12% of items initially routed to the robot queue ended up at the exception station due to pickability failures or bin location discrepancies. That's a manageable exception rate — human pickers cleared the exception queue within the same shift window — but it's only manageable because the exception routing preserved client attribution throughout. If the exception routing lost the client account code, billing attribution would have to be reconstructed manually from order IDs, which creates significant reconciliation labor.
Billing Accuracy as a First-Order Concern
Pick-level billing accuracy is a contractual obligation for most 3PLs, not just an operational nicety. When clients are billed per pick or per order line, the pick confirmation data is the source of truth for the invoice. Any ambiguity in which picks belong to which client account creates a dispute resolution process that costs both time and the client relationship.
The wave scheduling architecture described here — client-segregated at wave generation, client-attributed at pick confirmation, client-coded at exception routing — is designed to make the pick confirmation record unambiguous. When billing is run at end of period, each pick event traces cleanly to a client account code, a wave ID, and an order line. There's no reconciliation gap between the robot's confirmation log and the WMS billing record.
Getting this architecture designed correctly before deploying a pick cell is substantially easier than retrofitting it after six months of commingled confirmation data. If you're evaluating a pick cell deployment in your multi-tenant facility and want to walk through the wave scheduling configuration required for your specific WMS and client account structure, reach out for a pilot conversation.